Data-Driven Friction Analysis in Cloud Training
While supporting technical training at scale, I moved beyond anecdotal student feedback by architecting a 'Sidecar Ledger' in SQLite. This telemetry allowed me to quantify architectural bottlenecks and identify that 40% of all learner downtime originated from a single service domain.
Core Impact:
- Infrastructure Insight: Isolated Identity & Access Management (IAM) as the primary system friction point.
- Root Cause Analysis: Found that 83% of domain failures were Policy Misconfigurations rather than service outages.
- Operational Efficiency: Reallocated technical writing resources to reduce projected support volume by 25%.
- View SQL Logic on GitHub
The Methodology: From Feedback to Telemetry
1. Categorize
Mapping qualitative Slack logs and help tickets into a normalized SQLite relational model.
2. Quantify
Using SQL aggregation to identify the 'Magnitude of Failure' across AWS service domains.
3. Remediate
Implementing system-level validators and documentation refactors based on hard data.
Leveraging operational habits from my time at AWS, I treated the learner experience as a distributed system. By logging 'Error Signatures', I could see exactly where architectural complexity was outstripping the provided documentation, allowing for targeted engineering interventions.
Identifying System Bottlenecks
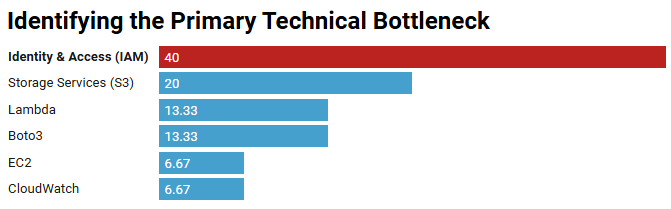
The following distribution was generated by querying the sidecar database. It revealed that while students complained most about complex Boto3 code, the actual blocker was almost always upstream in the IAM layer.
| Infrastructure Component | Total Incidents | % of Total Friction |
|---|---|---|
| Identity & Access (IAM) | 64 | 40.0% |
| Storage Services (S3) | 32 | 20.0% |
| Lambda / Boto3 | 42 | 26.6% |
| EC2 Compute | 11 | 6.7% |
| CloudWatch / Logs | 11 | 6.7% |
Root Cause & Remediation
By drilling down into the IAM domain, the data revealed that 83% of failures involved 'Principal' or 'iam:PassRole' misconfigurations. This clarity allowed for a precise two-pronged solution:
Technical Refactor
Automated Pre-Flight Checklists: I introduced validation scripts that use the AWS CLI to check for the presence of specific LabRoles before students attempt a deployment.
Content Refactor
Documentation Pivot: Reallocated 50% of technical writing efforts toward visual policy-logic flowcharts, neutralizing the highest frequency failure mode.
Closing Insight: Scaling technical training requires treating learner feedback as system telemetry. By applying an engineering mindset to "soft" feedback, we can identify the single points of failure holding back the entire cohort.